RCNN
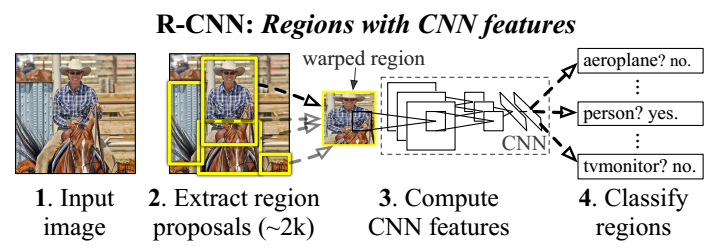
RCNN (Regions with CNN features) 的核心思想是把图像划分成N(2000)个独立的区域,分别提取每个区域的CNN特征,然后把这些特征使用SVM等分类器进行结果预测,把目标检测任务转换成了分类任务。RCNN由Ross Girshick在2013年提出。
RCNN算法的4个步骤:
1. 候选区域选择
选择候选区域就是进行区域提名(Region Proposal)操作,找出潜在的感兴趣区域。区域提名会提取到很多有重合区域的ROI,所以一般还会进行合并操作,综合考虑如色彩,灰度,轮廓等因素,既要保证不会漏掉有用的区域,又不至于重叠太多。Ross Girshick的RCNN论文中取了2000个区域候选狂。2. 区域大小归一化
把第一步提取到的候选区域执行大小归一化,论文中是归一化到227×227。3. CNN特征提取
对每一个归一化后的候选框区域执行标准的CNN过程,通过一系列卷积和池化操作,最后再通过2个全连接层,得到每个候选区域的固定维度的特征向量。4. 分类与边界回归
把步骤3中得到的特征向量使用SVM分类器(需要训练好基于CNN特征的SVM分类器)进行分类,用边界回归(Bounding-box regression)算法调整目标区域的位置,合并重叠区域,完成精确定位。
- 1. 重复计算,RCNN中的2000个候选框都要进行CNN操作,重复计算量很大。
- 2. 训练的空间和时间代价很高,RCNN中的区域提名、特征提取、分类和回归没能在一个流程中统一起来,有的需要单独离线进行,候选区域需要单独保存,占用磁盘空间较大。
- 3. 检测速度慢,在GPU上检测约需要13S,CPU上约需要53S。
SSP-net
2014年,何恺明等对RCNN进行了改进,提出SPP-net(Spatial Pyramid Pooling net),SPP-net相比RCNN的改进主要有两点:
一,使用空间金字塔方法实现维度归一化
去掉了RCNN中对原始图像进行的剪裁,拉伸缩放等归一化操作(这些warp操作导致物体的畸变,或几何失真),转而采用空间金字塔的方式,支持数据的多尺度输入。SPP-net的金字塔方法通过一个SPP层实现,加在最后一个卷积层后,第一个全连接层之前,实现了不同尺度的特征送入全连接层之前的维度归一化,二, 只对原图提取一次卷积特征,不再对每个候选区域单独执行CNN操作,在后边做一个候选区域的映射,对应到候选区域的特征上,减少了大量重复计算。
Fast-RCNN
2015年,Ross Girshick提出了 Fast-RCNN,Fast-RCNN结合了SPP-net的优点,主要为了解决2000个候选框带来的重复计算问题,提高训练和检测效率,主要思想是使用一个叫做 ROI Pooling的结构,可以看做是单层的SPP-net层,可以把不同维度的CNN特征归一化到统一维度,之后经过全连接层再softmax分类。梯度也可以通过这个ROI池化层直接传播,训练不再需要多步进行。实验结果表明,Fast RCNN的测试速度比RCNN快213倍,比SPP-net快10倍。
Faster RCNN
Faster RCNN利用 RPN(Region Proposal Network)网络来完成候选框的选取,取代了传统的区域提名方法。
RPN网络以任意大小的图片作为输入,输出一系列矩形区域提名,每个区域对应一个目标类别分数以及对应的位置信息。
Faster RCNN的主要步骤:- 1. 提取CNN特征,以整张图作为输入,只计算一次CNN
- 2. 区域提名,在最终的CNN特征上,为每个点利用9个不同的矩形框,提名候选区域
- 3. 区域判定和边界回归:先对每个候选矩形框进行目标物体和非目标物体的二分类,排除掉非目标物体的矩形框,再用9个回归模型(对应9个矩形框)微调候选框位置和大小。
- 4. 分类和边界回归,对步骤3中提供的候选框结果进行筛选,目标分类和边界回归。